In our earlier article Understanding Media – Measures of Central Tendency, we explained how to calculate the median for non-frequency type data, i.e. data where each observation occurred not more than once. In this article we shall try to explain how to calculate the median for frequency type data, i.e. data where each observation has a corresponding frequency of occurrence, i.e. the number of times that particular observation has occurred in our data. However, to do this we need to understand that the variable associated with the frequency type data can be of two types, viz. Discrete or Continuous. Refer to the articles An Introduction to Frequency Distribution and Frequency Distribution of Discrete and Continuous Variables to refresh your memory. It should be noted that when we are dealing with frequency type data, we are in fact, dealing with a frequency distribution of a certain variable. Now, that variable can be the number children in a family for all the families of a locality (discrete) or the height of boys and girls of a class (continuous).
Median for Frequency Type Data:
You will recollect that by definition, median of a data set is that value for which, the number of observations lying below that value is equal to the number of observations lying above that value, when the observations of the data set are arranged in ascending or descending order of magnitude. The median divides the entire data set into two equal halves. So, for frequency type data or rather for a frequency distribution of a variable, the process of calculating the value of the median involves cumulative frequency (less than type), but is different for discrete and continuous variables.
Median for Discrete Frequency Type Data (ungrouped data):
For frequency distribution of a discrete variable, to find the median we have need to look at the total frequency, 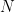

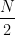
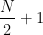
Example:
Frequency distribution of the number of students absent in a class of for one month (22 days of class in one month) is given below:
|
Number of students absent |
Number of days (frequency) |
|
0 |
2 |
|
1 |
1 |
|
2 |
4 |
| 3 |
10 |
|
4 |
3 |
| 5 |
2 |
| Total |
22 |
Find the median number of students absent.
Solution:
The table reads as follows:
There were 2 days in the month on which there were no absent students. (Row 1)
There was 1 day in the month on which there was 1 student absent. (Row 2)
There were 4 days in the month on which there were 2 students absent. (Row 3)
And so on…
We have to find the median number of students absent. For this, let us construct the cumulative frequency distribution (less than type) of the given table.
|
Number of students absent |
Number of days (frequency) |
Cumulative Frequency (less than type) |
|
0 |
2 | 2 |
|
1 |
1 |
3 |
|
2 |
4 |
7 |
|
3 |
10 |
17 |
|
4 |
3 |
20 |
|
5 |
2 |
22 |
| Total | 22 |
The new column reads as follows:
Row 1: There were 2 days on which the number of students absent was less than or equal to 0.
Row 2: There were a total 3 days on which the number of students absent was less than or equal to 1.
Row 3: There were a total of 7 days on which the number of students absent was less than or equal to 2.
And so on…
So, our data represented in the table is basically:
0, 0, 1, 1, 1, 2, 2, 2, 2, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 4, 4, 4, 5, 5
arranged in ascending order of magnitude.
Here, 
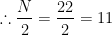

So, we have to consider the variate value corresponding to which the less than type cumulative frequency is just greater than or equal to 11 and the variate value corresponding to which the less than type cumulative frequency is just greater than or equal to 12.
From the lass than type cumulative frequency column we can see that the less than type cumulative frequency just greater than both 11 and 12 is 17 and the corresponding variate value is 3. What this means is that the middlemost values of the distribution are the 11th and 12th values, when arranged is ascending order of magnitude. In this case both the 11th and 12th variate values are equal to 3.

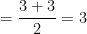
Half the days had number of absentees 3 or less and half the days had number of absentees 3 or more.
Note:
Here, it so happened that both the middlemost values were 3. It may so happen that the middlemost values are different. Let us take the following case:
|
Number of students absent |
Number of days (frequency) |
Cumulative Frequency (less than type) |
|
0 |
2 | 2 |
|
1 |
1 |
3 |
|
2 |
8 |
11 |
|
3 |
6 |
17 |
|
4 |
3 |
20 |
|
5 |
2 |
22 |
| Total | 22 |
Here, the frequency distribution is such that the the less than type cumulative frequency just greater than or equal to 
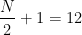
0, 0, 1, 2, 2, 2, 2, 2, 2, 2, 2, 3, 3, 3, 3, 3, 3, 4, 4, 4, 5, 5
So the median number of students absent in this case

But, median number of students cannot be 2.5 as number of students cannot be fractional. So we approximate 2.5 as 3.
Half the days had number of absentees less than 3 and half the days had number of absentees more than or equal to 3.
Note:
We do not say that half the days had number of absentees “equal to or less than” 3 because in the lower half, i.e. till the 11th variate value, the maximum number of absentees was 2. The upper half, starting from the 12th variate value contains variate values “equal to or more than” 3.
To conclude, the median value is 2.5, but the distribution is divided into two equal halves at either the 11th variate value, i.e 2 or the 12th variate value, i.e. 3. It is better that we take the variate value 3, because 2.5 approximates to 3 and not 2. However it should be mentioned that the variate value 3 is not included in the lower half of the distribution.
Note:
While finding out the median we need not or rather should not write down the entire set of variate values in ascending order. We can just use the formula to calculate the median value, using less than type cumulative frequency. In the above examples, we have written down the entire set of variate values in ascending order for the sole purpose of explaining the process more clearly.
For grouped frequency distribution of a discrete variable, the method for calculating the median is similar to that in case of frequency distribution of a continuous variable. These have been discussed in the article Measure of Central Tendency: Median 3.
Exercise:
1. The following table represents the frequency distribution of the number of children per family for 100 families in a locality:
|
Number of children |
Number of families |
|
0 |
23 |
|
1 |
26 |
|
2 |
37 |
|
3 |
11 |
| 4 |
3 |
| Total |
100 |
Find the median number of children per family.
2. Find the median of the following frequency distribution:
 |
Frequency |
| 15 | 21 |
| 25 | 15 |
| 35 | 24 |
| 45 | 8 |
| 55 | 4 |
| Total | 72 |
Very good explanation. Especially that question where “N/2=11 is 11 itself”. Explained greatly. Some books don’t have these examples but put such questions in exercises And in the exercises, they use wrong formula. But Mathstips first explain these and then give in exercise. Thanks a lot! 🙂